Last Updated: 2024–10-11
Background
At Datavolo, we take pride in creating simple solutions to complex problems. Datavolo runtimes not only offer a multitude of included processors, but allow users the flexibility to create custom processors. This extensibility ensures Datavolo can handle any requirement you may have.
Therefore, if your project exceeds the built-in capabilities, we made creating your own processors in Python a simple task.
Scope of the tutorial
In this tutorial, you will build a basic processor that transforms the contents of a FlowFile and emits it into the success relationship.
This tutorial is the first in a series of Python processor basics. You will use an existing flow that periodically creates a FlowFile whose content is a large JSON object. You will perform some transformations on the JSON to make it more useful in later tutorials.
This tutorial is part of the final goal of creating a full ETL pipeline that loads the data to a database by the end of the series.
Learning objectives
Once you've completed this tutorial, you will be able to:
- Write a Python class that extends FlowFileTransform.
- Properly leverage the ProcessorDetails class.
- Instantiate a FlowFileTransformResults object and route it to the success relationship.
- Package the processor code into a custom NAR file.
- Deploy the NAR file into a Datavolo runtime.
- Leverage the custom processor in a simple dataflow.
Prerequisites
- Basic Python development experience.
- Access to a Datavolo Cloud Runtime. See Datavolo Cloud: Getting started.
- Basic familiarization of building dataflows with Datavolo. See Build a simple NiFi flow.
Tutorial video
As an option, you can watch a video version of this tutorial.
Review the use case
For this tutorial, you will leverage an existing, but partial, dataflow that uses OpenSky's All State Vectors API call to populate the content of a FlowFlow. The content that is returned represents a list of thousands of flights that are airborne at any given moment.
This Opensky API responds with an object that contains a single states array. That array is simply of list of lists. The items in the inner list are values associated with a specific airborne flight. To unlock the features of all the powerful record processors in NiFi, this received structure needs to be flattened to a stream of flight record objects. This transform is a great example of where small bits of custom code can quickly be deployed to solve a problem.
Before and after sample data is presented below.
Input example
In addition to the list of lists problem described, the content has the following formatting issues.
- It is on one continuous line without any line breaks. It is shown below as multiple lines for readability.
- Many of the values in the JSON are represented as a list of values without any property names.
{
"time": 1727352646,
"states":
[
[
"ac96b8",
"AAL2728 ",
"United States",
1727352646,
1727352646,
-88.2722,
38.2925,
9395.46,
false,
242.99,
240.72,
7.48,
null,
9608.82,
"1127",
false,
0
],
[
"0ac9c3",
"AVA049 ",
"Colombia",
1727352643,
1727352643,
-74.5062,
4.263,
6019.8,
false,
214.39,
211.06,
8.45,
null,
6408.42,
null,
false,
0
]
]
}As defined in the API, each array within the states array includes values such as callsign (often a commercial flight number), the origin_country, and the last reported longitude & latitude location details.
Output example
In addition to using multiple lines in the output, consult the OpenSky API documentation to convert the arrays within the states array from simple lists of values into a JSON object with property names.
[
{
"icao24": "ac96b8",
"callsign": "AAL2728",
"origin_country": "United States",
"time_position": 1727352646,
"last_contact": 1727352646,
"longitude": -88.2722,
"latitude": 38.2925,
"on_ground": false,
"reporting_time": 1727352646
},
{
"icao24": "0ac9c3",
"callsign": "AVA049",
"origin_country": "Colombia",
"time_position": 1727352643,
"last_contact": 1727352643,
"longitude": -74.5062,
"latitude": 4.263,
"on_ground": false,
"reporting_time": 1727352646
}
]Initialize the canvas
Access a Runtime
Log into Datavolo Cloud and access (create if necessary) a Runtime. Alternatively, leverage a Datavolo Server Runtime that you have access to.
Import the template
Download the Tutorial__Python_transform_processor.json flow definition file and then import it onto the top-level NiFi Flow canvas.
After importing the flow definition file, you should see a process group (PG) named Tutorial__Python_transform_procesor on your canvas. Enter the PG to see the partial flow that looks similar to the following.
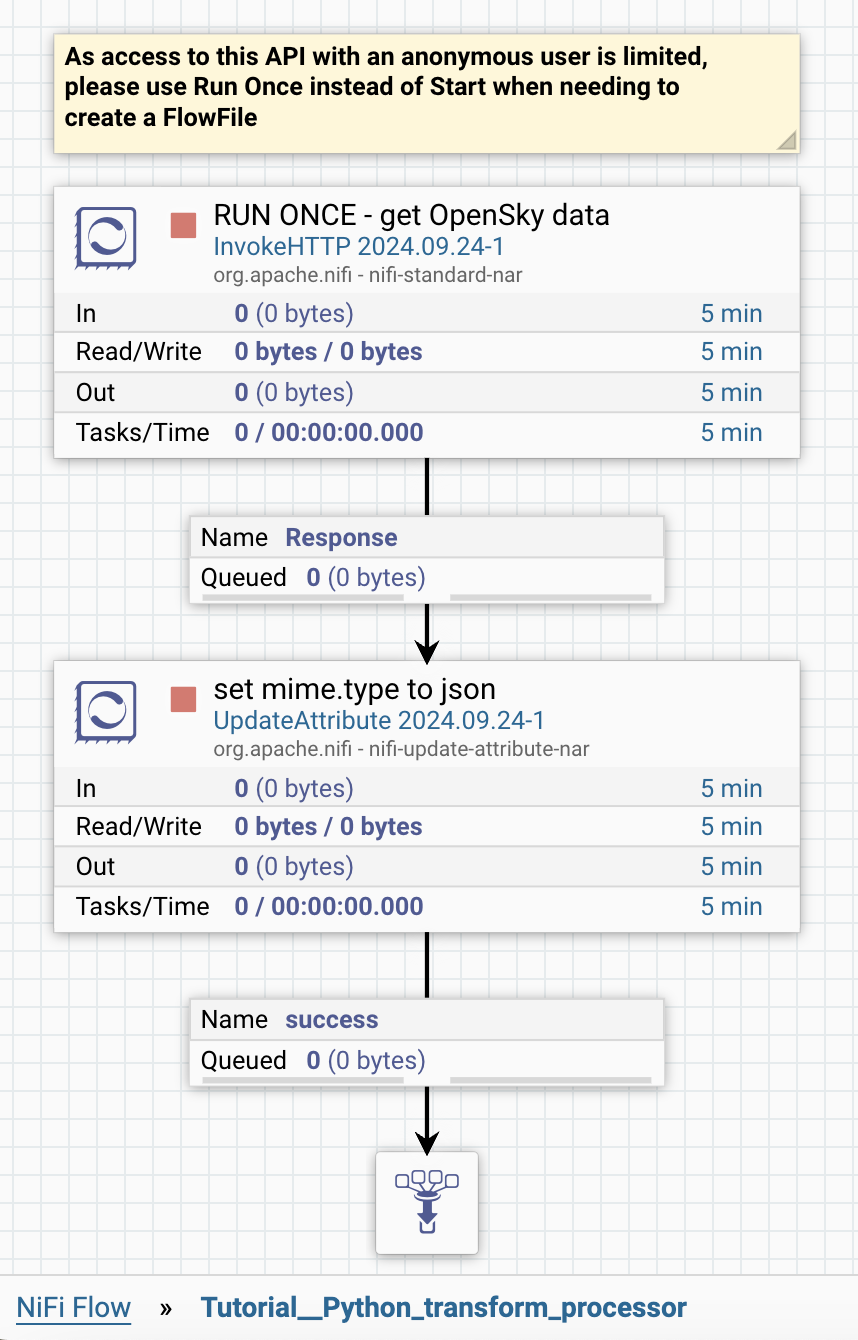
Initialize your development environment
Open the Datavolo Python Framework Overview documentation in your browser for reference during this tutorial. In an additional tab, load the Packaging Python Processors documentation as it has some project initialization steps we must follow.
As Packaging Python Processors indicates, make sure you have the necessary Python prerequisites and Hatch installed. Information is provided on that page for installation options, but this approach works if you have pipx installed.
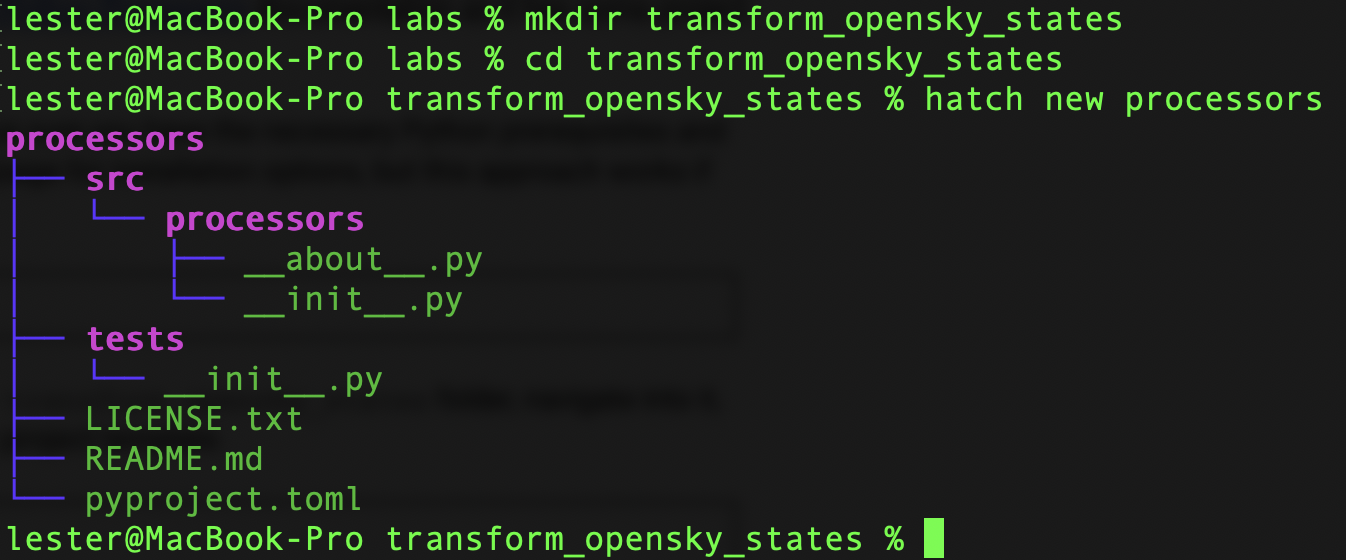
pipx install hatchIn a working directory of your choosing, create a transform_opensky_states folder, navigate into it, and run the following command to create a new project template.
hatch new processorsThe output should look similar to the following:
Replace the contents of the newly created pyproject.toml file with the following.
[build-system]
requires = ["hatchling", "hatch-datavolo-nar"]
build-backend = "hatchling.build"
[project]
name = "processors"
dynamic = ["version"]
dependencies = []
authors = [
{name="Your name", email="Your email"},
]
maintainers = [
{name="Your name", email="Your email"},
]
[tool.hatch.version]
path = "src/processors/__about__.py"
[tool.hatch.build.targets.nar]
packages = ["src/processors"]Creating a processor capable of transforming FlowFiles requires implementing a Python class that extends FlowFileTransform. The FlowFileTransform class provides an interface to access and modify FlowFile contents and attributes.
Extend FlowFileTransform
In the newly created ./transform_opensky_states/processors/src/processors folder, create a new Python source file named transform_opensky_states.py with the following code.
from nifiapi.flowfiletransform import (
FlowFileTransform,
FlowFileTransformResult
)
from nifiapi.properties import ProcessContext
class TransformOpenskyStates(FlowFileTransform):
class Java:
implements = ['org.apache.nifi.python.processor.FlowFileTransform']
class ProcessorDetails:
version = '0.0.1-SNAPSHOT'
description = '''
Transform the data returned by the OpenSky Network API.
'''
tags = ["opensky", "transform", "tutorial"]
dependencies = []
def __init__(self, **kwargs):
super().__init__()
def transform(
self, context: ProcessContext, flow_file
) -> FlowFileTransformResult:
'''
Parameters:
context (ProcessContext)
flow_file
Returns:
FlowFileTransformResult
'''
return FlowFileTransformResult("success")Class naming convention
The class name is important as it determines the processor name that is shown in the Datavolo UI. The convention is to put the action (verb) first, followed by the destination (noun). TransformOpenskyStates follows this convention.
The transform method
A custom processor based on FlowFileTransform requires a transform method, which will be called for each incoming FlowFile. This method holds the processor logic and is discussed further in the next step.
Understand ProcessorDetails
To use the processor, you need to include a ProcessorDetails instance with the attributes listed below and implemented above.
Name | Type | Description |
|
| Specifies the version of the processor |
|
| A short and concise blurb use to identify primary functionality |
|
| Keywords allowing for a quick search and access thought the Datavolo UI |
|
| Any external or additional packages required by the Processor to run |
Understand the transform method
The transform method contains the processor logic and is expected to return a FlowFileTransformResult object. Each FlowFileTransformResult object expects one positional argument, relationship, that describes the connection path between processors.
Depending on the relationship outcome, the FlowFile (and its related content) is routed to different destinations. By default, there are three relationships available to a FlowFileTransform processor; success, failure and original.
Implement the transform method
The goal for this first Python processor tutorial is to annotate the items of the states array with property names.
Load FlowFile contents
The data returned by the API is a valid JSON document, which can be easily digested by the loads method of the json Python module. Add the following line of code to the end of the existing import statements.
import jsonThe flow_file object supplied to the transform method exposes a getContentsAsBytes method, which returns the FlowFile contents represented as a Byte Array. Luckily, the json.loads method accepts bytes as an input.
Add the following line above the return statement in the transform method.
contents = json.loads(flow_file.getContentsAsBytes())Identify the order of properties
The order of the properties can be found in the OpenSky API documentation. Place a FIELD_MAP variable holding the ordered list of property names after the import statements.
FIELD_MAP = [
"icao24", "callsign", "origin_country", "time_position", "last_contact",
"longitude", "latitude", "baro_altitude", "on_ground", "velocity",
"true_track", "vertical_rate", "sensors", "geo_altitude", "squawk",
"spi", "position_source"
]Transform states array
You can now use the FIELD_MAP variable to annotate the items of the states array.
Place the following code below the contents = loads(flow_file.getContentsAsBytes()) line in the transform method.
states = []
for record in contents["states"]:
states.append(dict(zip(FIELD_MAP, record)))Here, you are creating a temporary variable, states, which will be used to hold the newly created dictionaries, before overriding the existing object.
Each record of the contents["states"] list is converted with the help of the built-in zip method. The goal is to combine the property names listed in the FIELD_MAP variable with the values stored in record to create annotated key-value pair representations. Those, in turn, need to be further converted into a dictionary before we can append them to the temporary states list.
Update the FlowFile
Replace the return FlowFileTransformResult("success") line in the transform method with the following to return the updated contents into the FlowFile.
return FlowFileTransformResult(
"success",
contents=json.dumps(states)
)Note that the contents parameter of the FlowFileTransformResult class accepts both Bytes and String values. Here, using the json.dumps method creates a string representing the updated state list.
Select a return schema
The goal of this example is to create a simplified version of the state record. The transformation will process only a selection of the data provided by the OpenSky API. Specifically, it will narrow the output to the most interesting information: plane identification, country of origin, location, and status (in flight or on the ground). This information is supplemented with timestamps: time of last contact and time of last location.
Here is how you can define a RETURN_SCHEMA, which should be placed under the FIELD_MAP variable.
RETURN_SCHEMA = [
"icao24", "callsign", "origin_country",
"time_position", "last_contact",
"longitude", "latitude", "on_ground"
]The following example shows how you can modify the existing one line body (i.e. states.append(...)) of the for record in ... loop to apply the RETURN_SCHEMA to the content.
states = []
for record in contents["states"]:
record = dict(zip(FIELD_MAP, record))
# Choose only fields listed in the RETURN_SCHEMA
sanitized = {}
for key, value in record.items():
if key not in RETURN_SCHEMA:
continue
sanitized[key] = value
states.append(sanitized)In the above code snippet, you create a new temporary variable, sanitized, to which only the relevant data points are assigned. After processing, the sanitized dictionary is appended to the states list.
Append reporting_time to record
The OpenSky states API endpoint provides a time property returned as part of every response. It can be useful to capture this property for each record.
You can directly reference the time property and assign it to the record. Add the following line after the existing record = dict(zip(FIELD_MAP, record)) one.
record["reporting_time"] = contents["time"]Remember to expand the RETURN_SCHEMA to include the newly created property. You can replace this whole block of code, or simply add "reporting_time", into it appropriately.
RETURN_SCHEMA = [
"icao24", "callsign", "origin_country",
"reporting_time", "time_position", "last_contact",
"longitude", "latitude", "on_ground"
]Sanitizing the data
Several fields contain superfluous white spaces that can be removed. In the following example, we introduce a simple method of sanitizing the strings by trimming any preceding or trailing white spaces.
You can add the following code snippet below contents = loads(flow_file.getContentsAsBytes()).
def sanitize_value(value):
if isinstance(value, str):
return value.strip()
return valueWith that out of the way, you can proceed with the final transformation and process the value before assigning it to the temporary sanitized variable. Update the line of code beginning with sanitized[key] as shown below.
sanitized[key] = sanitize_value(value)Overview
In this simple implementation, you created a basic Python processor for transforming API data. You started by defining a class that extends FlowFileTransform, where you declared the description, tags, and dependencies. Then, you added functionality within the transform method, learning how to access the flow_file contents, modify the response data, and assign the updated contents back to the FlowFile.
Source listing
Here is what your transform_opensky_states.py source file should look like at this time.
from nifiapi.flowfiletransform import (
FlowFileTransform,
FlowFileTransformResult
)
from nifiapi.properties import ProcessContext
import json
FIELD_MAP = [
"icao24", "callsign", "origin_country", "time_position", "last_contact",
"longitude", "latitude", "baro_altitude", "on_ground", "velocity",
"true_track", "vertical_rate", "sensors", "geo_altitude", "squawk",
"spi", "position_source"
]
RETURN_SCHEMA = [
"icao24", "callsign", "origin_country",
"reporting_time", "time_position", "last_contact",
"longitude", "latitude", "on_ground"
]
class TransformOpenskyStates(FlowFileTransform):
class Java:
implements = ['org.apache.nifi.python.processor.FlowFileTransform']
class ProcessorDetails:
version = '0.0.1-SNAPSHOT'
description = '''
Transform the data returned by the OpenSky Network API.
'''
tags = ["opensky", "transform", "tutorial"]
dependencies = []
def __init__(self, **kwargs):
super().__init__()
def transform(
self, context: ProcessContext, flow_file
) -> FlowFileTransformResult:
'''
Parameters:
context (ProcessContext)
flow_file
Returns:
FlowFileTransformResult
'''
contents = json.loads(flow_file.getContentsAsBytes())
def sanitize_value(value):
if isinstance(value, str):
return value.strip()
return value
states = []
for record in contents["states"]:
record = dict(zip(FIELD_MAP, record))
record["reporting_time"] = contents["time"]
# Choose only fields listed in the RETURN_SCHEMA
sanitized = {}
for key, value in record.items():
if key not in RETURN_SCHEMA:
continue
sanitized[key] = sanitize_value(value)
states.append(sanitized)
return FlowFileTransformResult(
"success",
contents=json.dumps(states)
)Package the NAR
A NAR file is a packaged bundle used in Datavolo to distribute processors, controller services, and other extensions. Now, with the processor code ready you can run the following command to create your package.
hatch build --target narThe output will show you the location of the generated .nar file.

Deploy the NAR
Now that you have created a NAR file for your processor, you can deploy it into a Datavolo runtime.
Back on the canvas, choose Controller Settings from the navigation drawer (aka hamburger menu) on the far right of the UI then navigate to the Local Extensions tab and click on the + icon on the far right.
Select the newly created NAR file in the chooser window that surfaces and verify the NAR reports as Installed.

Generate a FlowFile
Back on the canvas, inside the Tutorial__Python_transform_processor PG, Start the set mime.type to json processor and then Run Once (not Start) the RUN ONCE - get OpenSky data processor.
Verify that the RUN ONCE - get OpenSky data processor is in a Stopped state and that there is a single FlowFile in the connection to the funnel.
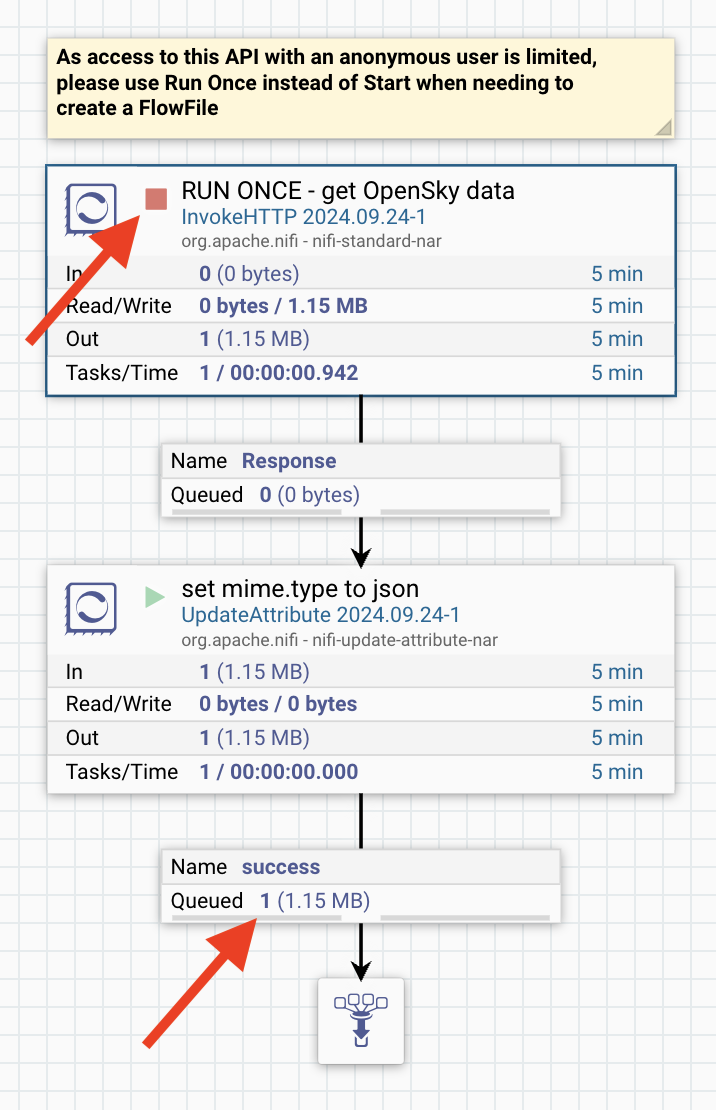
Inspect the input data
List Queue and then View content of the single FlowFile present in the queue.
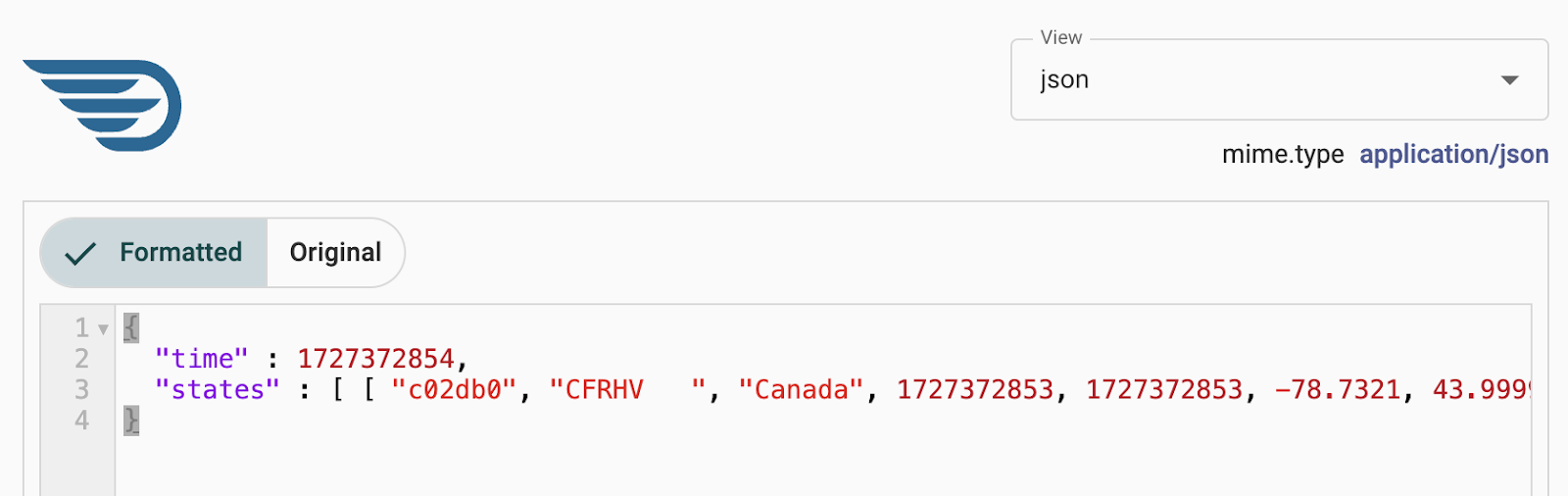
This is an Input example as shown in the Review the use case section.
Configure/execute the custom processor
Back on the canvas, perform these steps.
- Add a TransformOpenskyStates processor.
- Connect the existing funnel to the new processor.
- Create a new funnel and connect the success relationship from the new processor to it.
- Auto-terminate the failure relationship.
- Run the new processor.
As shown below, the queue above the new processor should now be empty and the success relationship's queue should have a single FlowFile in it now.
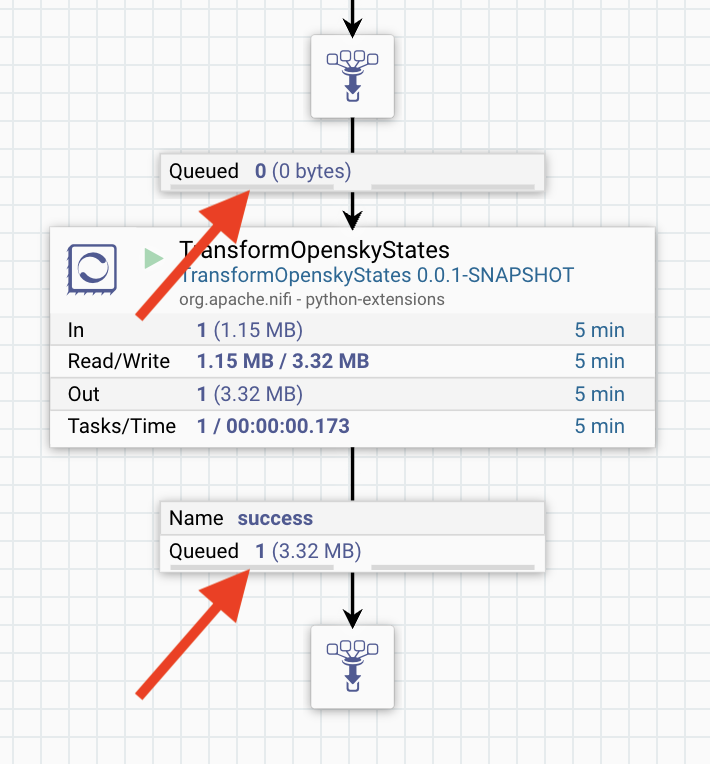
Inspect the transformed data
List Queue and then View content of the single FlowFile present in the queue.
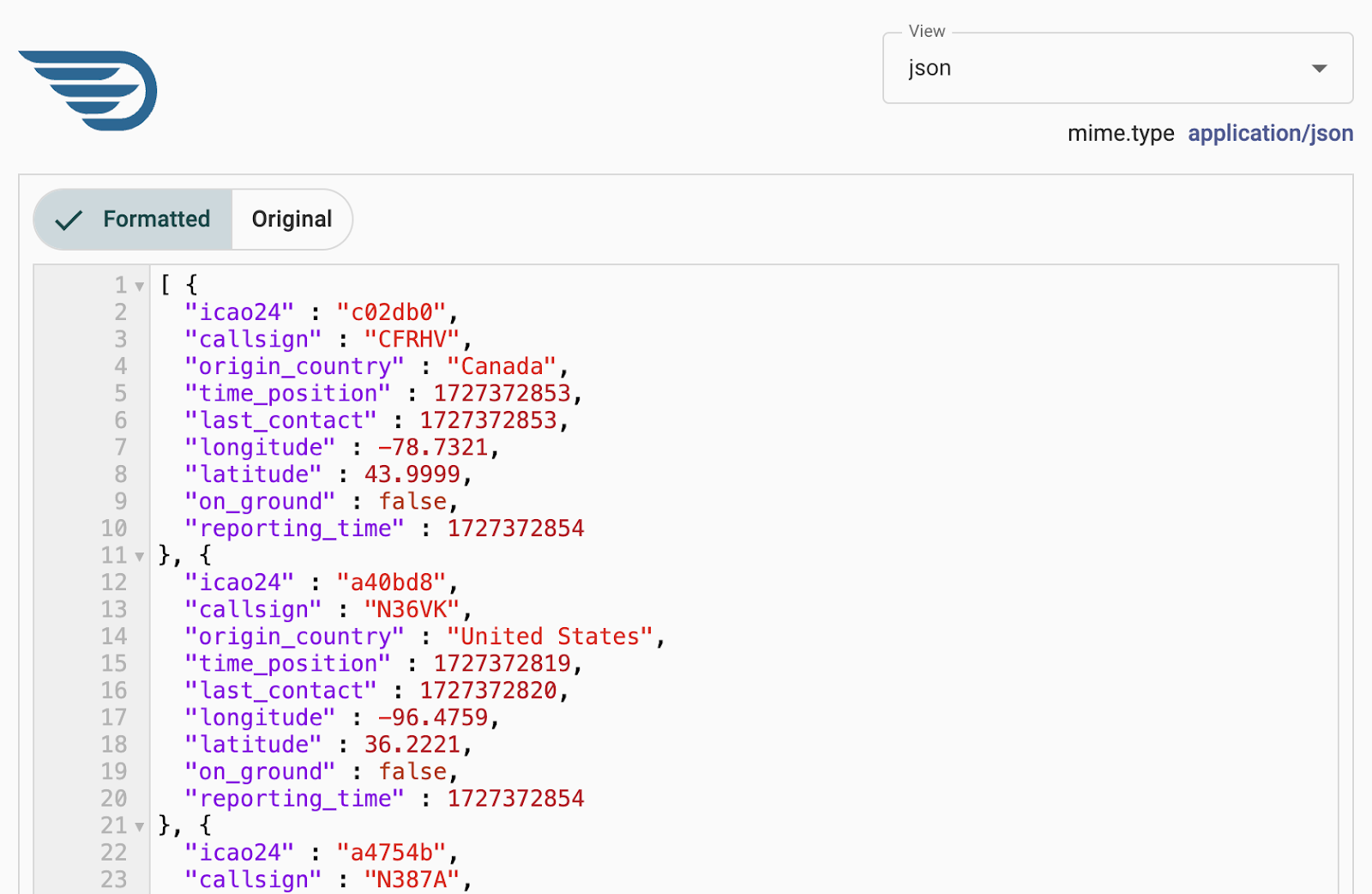
This is an Output example as shown in the Review the use case section. Notice the property names are present for the values in each flattened object in the list. Additionally, line breaks are present to aid readability.
Congratulations, you've completed the Build a NiFi Python transform processor tutorial!
What you learned
- How to write a Python class that extends FlowFileTransform.
- How to properly leverage the ProcessorDetails class.
- How to instantiate a FlowFileTransformResults object and route it to the success relationship.
- How to package the processor code into a custom NAR file.
- How to deploy the NAR file into a Datavolo runtime.
- How to leverage the custom processor in a simple dataflow.
What's next?
Check out some of these codelabs...